Automatic speech tools are getting good, but they are not magic. They can produce transcripts, segment boundaries, word timings, phones, tiers, and labels, but someone still has to check them. In real speech data, especially conversational data, the useful work often begins after automatic alignment.
Movak is built for that moment.
It is a Python desktop application for inspecting, correcting, and navigating speech annotations. The basic idea is familiar from tools like Praat: open an audio file, look at the waveform and spectrogram, listen carefully, inspect the annotations, and fix what needs fixing. But Movak aims to approach this workflow as a modern annotation workspace rather than a single-purpose legacy editor.
The central use case is post-alignment correction. An automatic system has already done the first pass: perhaps it has detected speech regions, aligned words, generated tiers, or proposed segment boundaries. Movak gives the human annotator a place to review those outputs efficiently, move through the audio, adjust boundaries, relabel intervals, split and merge regions, and keep track of the editing process.
This matters because speech annotation is not just transcription. Timing is part of the data. A boundary that is off by 200 milliseconds can matter for phonetics, turn-taking, EEG alignment, acoustic analysis, or conversational timing. Movak is designed around that reality: the user needs to see the signal, hear the signal, and edit the annotation in relation to the signal.
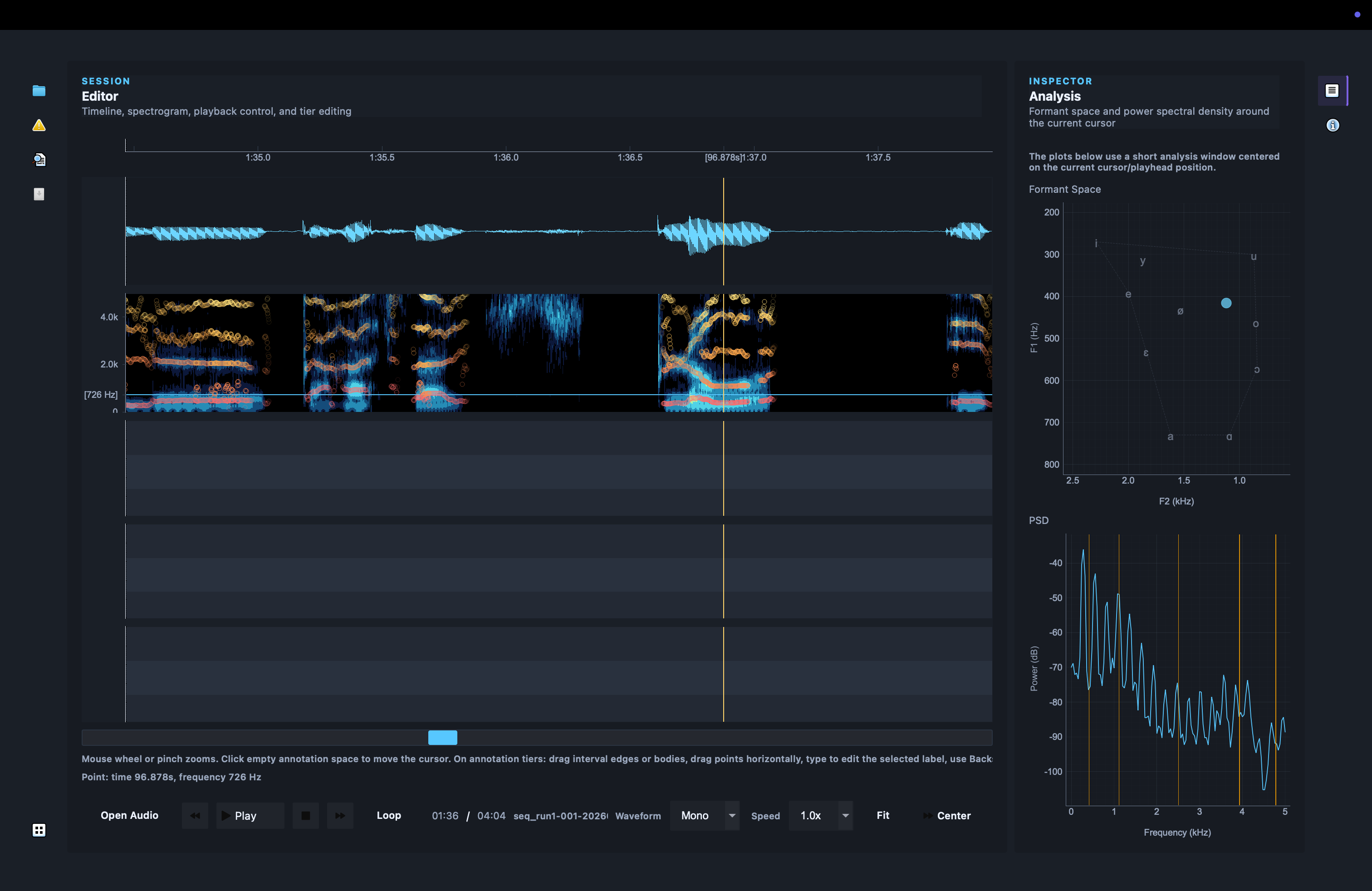
The workspace is organized like a small annotation IDE. The center of the application is the audio timeline: waveform, spectrogram, transport controls, cursor movement, zooming, panning, selection, and loop-style playback. The left side is for corpus-level navigation, search, review, and export-oriented tools. The right side is for analysis and inspection. The bottom panel supports review-oriented workflows. The goal is not just to display annotations, but to support the whole process of moving through a dataset and improving it.
A key design idea is modularity. Movak separates the core data models from the GUI, the annotation operations, the audio layer, the timeline rendering, acoustic features, query logic, and import/export surfaces. That makes the project more than a GUI experiment. It is an attempt to build speech annotation software as an extensible application: one where editing operations, acoustic analysis, plugins, and assisted correction can grow without turning the codebase into spaghetti.
The long-term vision is a tool that sits between automatic speech processing and careful human curation. Automatic alignment systems can do the rough work. Movak can become the place where researchers refine those outputs into trustworthy annotations: correcting intervals, inspecting acoustic evidence, checking tiers, searching tokens, reviewing suspicious regions, and eventually using AI-assisted workflows to speed up the boring parts without giving up human control.
This is especially useful for research data. Conversational speech, child speech, second-language speech, clinical speech, field recordings, and experimental audio all tend to break clean assumptions. A good annotation editor needs to handle messy timing, repeated correction, visual inspection, and project-level organization. Movak is being shaped around exactly that kind of mess.
So the short version is: Movak is a modern speech-annotation editor for the post-automatic-alignment era. It aims to make human correction faster, more inspectable, and more pleasant by combining audio playback, waveform and spectrogram views, timeline navigation, editable annotation tiers, acoustic inspection, and a modular application architecture. Its broader goal is to become a practical bridge between automatic speech tools and high-quality research annotations.